线代笔记整理
写在前面: 这份讲义是笔者在学习时的一些思考和题目复盘。尤其想说的是,在2025-2026年的期末考里,讲义里不少核心思路和题目都“押中”了。
关于这份讲义: 笔记的初稿是笔者自己整理的,后来在Gemini的帮助下重新梳理了逻辑、调整了排版。
比起复杂的行列式计算,笔者总觉得几何直觉(Geometric Intuition) 更自然,也更能帮助理解本质。所以如果你在读的时候,发现里面有不少从几何角度出发的解释——嗯,那大概就是笔者个人偏好了。
🛫 第 零 章:矩阵乘法的本源 (The Origins)
可以用以下五种视角进行矩阵运算的理解。
0.1 矩阵乘向量:\(Ax\) 的两种核心视角
设 \(A = \begin{pmatrix} \mathbf{c}_1 & \mathbf{c}_2 & \dots & \mathbf{c}_n \end{pmatrix}\),其中 \(\mathbf{c}_i\) 是列向量。
视角 A:列的线性组合 (The Column Picture) —— 最重要!
\[A \mathbf{x} = \begin{pmatrix} \mathbf{c}_1 & \mathbf{c}_2 & \dots & \mathbf{c}_n \end{pmatrix} \begin{pmatrix} x_1 \\ \vdots \\ x_n \end{pmatrix} = x_1 \mathbf{c}_1 + x_2 \mathbf{c}_2 + \dots + x_n \mathbf{c}_n\]
直觉: \(Ax\) 是对 \(A\) 的列向量进行线性组合。
应用:
解方程 \(Ax=b\): 实际上是在问“能不能用 \(A\) 的列向量组合出 \(b\)?”(即 \(b\) 是否在列空间里)。
列空间 \(C(A)\): 就是所有这些组合 \(Ax\) 构成的集合。
视角 B:行的点积 (The Row Picture)
\[A \mathbf{x} = \begin{pmatrix} \mathbf{r}_1^T \\ \vdots \\ \mathbf{r}_m^T \end{pmatrix} \mathbf{x} = \begin{pmatrix} \mathbf{r}_1^T \cdot \mathbf{x} \\ \vdots \\ \mathbf{r}_m^T \cdot \mathbf{x} \end{pmatrix}\]
直觉: 看作 \(x\) 在 \(A\) 的每一行方向上的投影。
应用: 在 \(Ax=0\) 中,意味着 \(x\) 必须垂直于 \(A\) 的每一行(所以零空间 \(\perp\) 行空间)。
0.2 向量乘矩阵:\(y^T A\)
\[\mathbf{y}^T A = \begin{pmatrix} y_1 & \dots & y_m \end{pmatrix} \begin{pmatrix} \mathbf{r}_1^T \\ \vdots \\ \mathbf{r}_m^T \end{pmatrix} = y_1 \mathbf{r}_1^T + \dots + y_m \mathbf{r}_m^T\]
直觉: \(y^T A\) 是对 \(A\) 的行向量进行线性组合。
口诀: 左乘行组合,右乘列组合。
0.3 矩阵乘矩阵:\(AB\) 的四种视角
设 \(A_{m \times n}\),\(B_{n \times p}\)
视角 A:列操作 (Column-wise) —— \(A\) 作用于 \(B\) 的列
把 \(B\) 看作一堆列向量 \(\begin{pmatrix} \mathbf{b}_1 & \dots & \mathbf{b}_p \end{pmatrix}\)。
\[AB = A \begin{pmatrix} \mathbf{b}_1 & \dots & \mathbf{b}_p \end{pmatrix} = \begin{pmatrix} A\mathbf{b}_1 & \dots & A\mathbf{b}_p \end{pmatrix}\]
直觉: \(AB\) 的第 \(j\) 列,是 \(A\) 对 \(B\) 的第 \(j\) 列做变换。
结论: \(AB\) 的列空间是 \(A\) 的列空间的子空间。
视角 2:行操作 (Row-wise) —— \(B\) 作用于 \(A\) 的行
把 \(A\) 看作一堆行向量。
\[AB = \begin{pmatrix} \mathbf{a}_1^T \\ \vdots \\ \mathbf{a}_m^T \end{pmatrix} B = \begin{pmatrix} \mathbf{a}_1^T B \\ \vdots \\ \mathbf{a}_m^T B \end{pmatrix}\]
直觉: \(AB\) 的第 \(i\) 行,是 \(B\) 对 \(A\) 的第 \(i\) 行做组合。
结论: \(AB\) 的行空间是 \(B\) 的行空间的子空间。
视角 3:列乘行 (Outer Product Expansion) —— 高阶大招
这是谱分解和SVD的灵魂。
\[AB = \sum_{k=1}^n (\text{A的第k列}) \times (\text{B的第k行}) = \mathbf{c}_1 \mathbf{r}_1^T + \mathbf{c}_2 \mathbf{r}_2^T + \dots + \mathbf{c}_n \mathbf{r}_n^T\]
直觉: 矩阵乘法是 \(n\) 个秩1矩阵的和。
应用:
谱分解: \(A = \sum \lambda_i q_i q_i^T\) 其实就是这个视角。
SVD: \(A = \sum \sigma_i u_i v_i^T\) 也是这个视角。
如果只需近似矩阵,取前几项相加即可(主成分分析)。
0.4 变换的黄金法则 (The Golden Rule)
这是 Gilbert Strang 老爷子反复强调的:
Left Multiply = Row Operation (左乘做行变换)
Right Multiply = Column Operation (右乘做列变换)
想对 \(A\) 做行变换(高斯消元)?
在 \(A\) 的左边乘一个初等矩阵 \(E\)。
\[EA = \text{对A的行进行组合}\]
想对 \(A\) 做列变换?
在 \(A\) 的右边乘一个初等矩阵 \(E\)。
\[AE = \text{对A的列进行组合}\]
举个栗子🌰:
\(A^{-1}A = I\): 用 \(A^{-1}\) 在左边不断乘,相当于做初等行变换把 \(A\) 变成 \(I\)。
\(AP = B\): \(P\) 在右边,说明 \(B\) 是 \(A\) 的列的重新排列或组合(比如交换两列)。
🚀 第一章:分块矩阵与行列式 (The Block Art)
1.1 分块对角/反对角矩阵求逆
遇到分块矩阵,不要死算,看结构。
分块对角阵求逆: 直接对角线求逆。
\[ \begin{pmatrix} A_1 & & \\ & \ddots & \\ & & A_n \end{pmatrix}^{-1} = \begin{pmatrix} A_1^{-1} & & \\ & \ddots & \\ & & A_n^{-1} \end{pmatrix}\]
分块反对角阵求逆: 注意! 逆矩阵的顺序是反过来的,且位置维持反对角。
\[ \begin{pmatrix} & & A_1 \\ & \dots & \\ A_n & & \end{pmatrix}^{-1} = \begin{pmatrix} & & A_n^{-1} \\ & \dots & \\ A_1^{-1} & & \end{pmatrix}\]
1.2 舒尔补公式 (Schur Complement) —— 行列式降维神器
口诀: 提主元,扣尾款。
当 \(A\) 可逆时(以 \(A\) 为主元):
\[\begin{vmatrix} A & B \\ C & D \end{vmatrix} = |A| \cdot |D - C A^{-1} B|\]
当 \(D\) 可逆时(以 \(D\) 为主元):
\[\begin{vmatrix} A & B \\ C & D \end{vmatrix} = |D| \cdot |A - B D^{-1} C|\]
直觉来源: 这本质上是分块高斯消元:
\[\begin{pmatrix} I & 0 \\ -CA^{-1} & I \end{pmatrix} \begin{pmatrix} A & B \\ C & D \end{pmatrix} = \begin{pmatrix} A & B \\ 0 & D - CA^{-1}B \end{pmatrix}\]
1.3 降阶公式 (Sylvester’s Determinant Identity)
当矩阵维度不同时(\(A_{m \times n}, B_{n \times m}\)),这是连接两个维度的桥梁。
\[|\lambda E_m - AB| = \lambda^{m-n} |\lambda E_n - BA|\]
特例(\(\lambda=1\)):
\[|E_m - AB| = |E_n - BA|\]
应用: 如果 \(A\) 是列向量 \(u\), \(B\) 是行向量 \(v^T\),则 \(AB\) 是大矩阵,\(BA\) 是标量!
1.4 秩1修正行列式 (Matrix Determinant Lemma)
这是上述降阶公式的推论,用于处理“单位阵+秩1矩阵”。
\[|A + \mathbf{u}\mathbf{v}^T| = |A|(1 + \mathbf{v}^T A^{-1} \mathbf{u})\]
常见考题形式(\(A=I, u=\alpha, v=-\alpha\)):
\[|I - \alpha\alpha^T| = 1 - \alpha^T \alpha\]
🛠 第二章:矩阵求逆进阶 (Inverse Pro)
2.1 秩1修正求逆 (Sherman-Morrison Formula)
\[(A + uv^T)^{-1} = A^{-1} - \frac{A^{-1}uv^TA^{-1}}{1 + v^TA^{-1}u}\]
特例(当 \(A=I\)):
\[(I - uv^T)^{-1} = I + \frac{uv^T}{1 - v^T u}\]
记忆法:
符号相反(左边加,右边减)。
分母是标量 \(1+\text{trace}\)。
分子被 \(A^{-1}\) 夹在中间。
2.2 二阶矩阵求逆口诀
\[\begin{pmatrix} a & b \\ c & d \end{pmatrix}^{-1} = \frac{1}{ad-bc} \begin{pmatrix} d & -b \\ -c & a \end{pmatrix}\]
口诀: 主对调,副变号,除以行列式。
📈 第三章:秩与不等式 (Rank & Inequalities)
3.1 秩的重要连等式
\[r(A) = r(A^T A) = r(A^T) = r(AA^T)\]
推论: \(Ax=0\) 与 \(A^TAx=0\) 是同解方程组。(最小二乘法的理论基础)
3.1.0 拓展:投影矩阵与最小二乘
现实世界是不完美的。
当方程组 \(Ax=b\) 无解时(比如 \(b\) 不在 \(A\) 的列空间里),工程思维不是“两手一摊”,而是 “退而求其次” 。
我们找不到精确解,但我们可以找“最近的解”(误差最小的解)。
3.1.1 最小二乘法 (Least Squares)
问题: \(b\) 飞出去了,不在 \(A\) 的管辖范围(列空间)里。
目标: 在 \(A\) 的列空间里找一个替身 \(p\),让 \(p\) 离 \(b\) 最近。几何上,这意味着 \(b-p\)(误差向量 \(e\))必须垂直于 \(A\) 的列空间。
核心方程 (Normal Equation): \[A^T A \hat{x} = A^T b\]
3.1.2 投影矩阵 (Projection Matrix \(P\))
公式:
\[P = A(A^T A)^{-1} A^T\]
(推导:因为 \(p = A\hat{x}\),把上面解出来的 \(\hat{x}\) 带进去即得)
若 \(A\) 为列向量 \(a\)(投影到直线): \[P = \frac{aa^T}{a^Ta}\]
3.1.3 灵魂性质:幂等性 (\(P^2 = P\))
代数意义: \(P^2 = P \cdot P = P\)。
几何直觉:
把一个向量投影到桌面上(变成了影子)。
再对这个影子做一次投影。
结论: 投影两次 = 投影一次。
3.2 秩的不等式链条
和的秩: \(r(A+B) \le r(A) + r(B)\)
积的秩: \(r(AB) \le \min \{ r(A), r(B) \}\)
分块矩阵的秩:
\[ \max \{r(A), r(B)\} \le r(A \quad B) \le r(A) + r(B)\]
\[ r \begin{pmatrix} A & 0 \\ 0 & B \end{pmatrix} = r(A) + r(B)\]
\[ r \begin{pmatrix} A & 0 \\ C & B \end{pmatrix} \ge r(A) + r(B)\]
西尔维斯特不等式 (Sylvester): \(r(AB) \ge r(A) + r(B) - n\) (其中 \(A_{m \times n}, B_{n \times s}\))
🌀 第四章:特征值与对角化 (Eigenvalues)
4.0 特征值两大结论
迹 (Trace): \(\sum \lambda_i = \text{tr}(A) = \sum a_{ii}\)
行列式 (Determinant): \(\prod \lambda_i = |A|\)
4.1 普通矩阵可对角化判据
\(n\) 阶矩阵 \(A\) 可对角化 \(\iff\) 有 \(n\) 个线性无关特征向量。
判别流程:
无重根: \(\lambda\) 互异 \(\Rightarrow\) 必可对角化。
有重根: 若 \(\lambda_i\) 是 \(k\) 重根,必须检查 几何重数 == 代数重数。
即:\(n - r(A - \lambda_i I) = k\)。
(缺一个特征向量都不能对角化!)
4.2 秩1矩阵的特征值 (\(\alpha \beta^T\))
对于矩阵 \(C = \alpha \beta^T\)(秩为1):
特征值 \(\lambda_1\): 等于迹,即 \(\text{tr}(C) = \beta^T \alpha\)。
其余特征值: 全为 \(0\)。
特征向量:
对应非零特征值的特征向量是 \(\alpha\) (\(C \alpha = \alpha (\beta^T \alpha)\))。
对应0特征值的特征向量是所有垂直于 \(\beta\) 的向量。
4.3 秩1修正矩阵 (\(E - k\alpha\alpha^T\)) 的特征值
这类矩阵在几何上对应“反射”或“压缩”,在Householder变换中极常见。
对于矩阵 \(B = E - k \alpha \alpha^T\)(\(E\)为单位阵):
特征值:
主特征值: \(\lambda_1 = 1 - k(\alpha^T \alpha)\) (对应特征向量 \(\alpha\))。
重特征值: 其余 \(n-1\) 个特征值均为 \(1\) (对应特征向量为所有垂直于 \(\alpha\) 的向量)。
行列式: \(|B| = \prod \lambda_i = 1 - k(\alpha^T \alpha)\)。
几何直觉:
矩阵只在 \(\alpha\) 方向上进行了缩放(缩放倍数为 \(1 - k|\alpha|^2\))。
在垂直于 \(\alpha\) 的平面上,它就是单位阵 \(E\)(没动)。
一般推广 (Rank-1 Update):
对于 \(C = A + \mathbf{u}\mathbf{v}^T\),若已知 \(A\) 的特征值,通常无法直接求 \(C\) 的特征值。
但如果 \(A = \lambda I\)(即 \(C = \lambda I + \mathbf{u}\mathbf{v}^T\)),则结论同上:
一个特征值为 \(\lambda + \mathbf{v}^T \mathbf{u}\),其余为 \(\lambda\)。
4.4 实对称矩阵 (Real Symmetric Matrix)
最好的矩阵: \(A = A^T\)
特征值全为实数。
不同特征值对应的特征向量天然正交。
必可正交对角化:\(Q^T A Q = \Lambda\) (\(Q\)为正交阵)。
4.5 谱分解的高阶处理 (Spectral Decomposition Pro)
实对称矩阵可以分解为 \(n\) 个投影矩阵的加权和:
\[A = \lambda_1 P_1 + \lambda_2 P_2 + \dots + \lambda_n P_n\]
其中 \(P_i = q_i q_i^T\) 是向第 \(i\) 个特征方向的投影矩阵。
4.6 特征向量速算外挂:叉积法 (Cross Product Trick)
仅适用于 3阶矩阵 (\(n=3\)) 的手算神器。
当求 \(3\times 3\) 矩阵 \(A\) 对应特征值 \(\lambda\) 的特征向量 \(x\) 时,我们需要解 \((A - \lambda I)x = 0\)。
传统方法: 高斯消元,容易算错。
叉积外挂:
写出矩阵 \(M = A - \lambda I\)。
因为 \(M\) 是奇异的(秩<3),它的行向量线性相关。
任选 \(M\) 中两个不共线的行向量 \(r_1, r_2\)(看都不用看直接选非零且不成比例的两行)。
直接计算叉积:\(x = r_1 \times r_2\)。
得到的 \(x\) 即为特征向量(无需归一化)。
原理: \(Mx=0\) 意味着 \(x\) 垂直于 \(M\) 的每一行。三维空间中同时垂直于两个向量的方向,就是它们的叉积方向。
注意: 如果算出是 \(\mathbf{0}\),说明选的两行共线了,换两行再叉即可。
📐 第五章:空间与变换 (Spaces & Geometry)
5.1 线性变换判定
映射 \(T: V \to W\) 是线性的,必须同时满足:
加法性: \(T(\alpha + \beta) = T(\alpha) + T(\beta)\)
齐次性: \(T(k\alpha) = k T(\alpha)\)
避坑指南:
检查 \(T(\mathbf{0})\) 是否为 \(\mathbf{0}\)。如果 \(T(x) = x + b\) (\(b \neq 0\)),那是平移,不是线性变换。
出现平方、取模、行列式运算通常不是线性变换。
5.2 欧氏空间与内积判定
一个运算 \(\langle \alpha, \beta \rangle\) 要成为内积,必须满足 4 条公理:
对称性: \(\langle \alpha, \beta \rangle = \langle \beta, \alpha \rangle\)
线性(对第一变元): \(\langle k\alpha + l\beta, \gamma \rangle = k\langle \alpha, \gamma \rangle + l\langle \beta, \gamma \rangle\)
非负性: \(\langle \alpha, \alpha \rangle \ge 0\)
严格正性: \(\langle \alpha, \alpha \rangle = 0 \iff \alpha = \mathbf{0}\)
5.3 空间相等的证明
要证明线性空间 \(V_1 = V_2\),通常只需证两点:
包含关系: \(V_1 \subseteq V_2\) (即 \(V_1\) 的基都能被 \(V_2\) 的基线性表示)。
维数相等: \(\dim(V_1) = \dim(V_2)\)。
5.4 施密特正交化 (Gram-Schmidt Orthogonalization)
1. 核心直觉 (The Intuition)
给我们一组“乱七八糟、互相歪斜”的基 \(\alpha_1, \alpha_2, \dots\),我们想把它们变成一组“横平竖直、互相垂直”的基 \(\beta_1, \beta_2, \dots\)
做法: 也就是 “去投影”
保留第一个向量不动
第二个向量 = 原来的第二个 - (在第一个上的影子)
第三个向量 = 原来的第三个 - (在第一个上的影子) - (在第二个上的影子)
2. 计算公式 (The Algorithm)
设原向量组为 \(\alpha_1, \alpha_2, \alpha_3\)
Step 1 (定基准):
\[\beta_1 = \alpha_1\]
Step 2 (去投影):
\[\beta_2 = \alpha_2 - \frac{\langle \alpha_2, \beta_1 \rangle}{\langle \beta_1, \beta_1 \rangle} \beta_1\]
Step 3 (如法炮制):
\[\beta_3 = \alpha_3 - \frac{\langle \alpha_3, \beta_1 \rangle}{\langle \beta_1, \beta_1 \rangle} \beta_1 - \frac{\langle \alpha_3, \beta_2 \rangle}{\langle \beta_2, \beta_2 \rangle} \beta_2\]
最后一步(单位化): 如果题目要求“标准正交基”,别忘了最后除以模长:\(\eta_i = \frac{\beta_i}{|\beta_i|}\)。
3. 避坑指南 (The Trap)
对象搞错: 公式里减去的投影,是基于已经正交化好的 \(\beta_1, \beta_2\),绝对不是基于原来的 \(\alpha_1, \alpha_2\)!
错解: \(\beta_3 = \alpha_3 - k_1 \alpha_1 - k_2 \alpha_2\) (❌)
正解: \(\beta_3 = \alpha_3 - k_1 \beta_1 - k_2 \beta_2\)
计算量爆炸: 如果在中间过程就急着“单位化”(带上了根号),后面的计算会算到怀疑人生。
- 策略: 先只做正交化(只搞垂直,不管长短),算出清爽的整数 \(\beta_i\),最后再统一除以模长。
🎢 第六章:二次型与合同 (Quadratic Forms & Congruence)
如何理解?
二次型 \(f(x) = x^T A x\) 描述的是一个 “地势图”。
我们做的所有变换(配方、正交变换),都是在不改变地形凹凸性质的前提下,换个角度看这个地势。
- 正定 = 碗(有最低点,稳定)
- 负定 = 山峰(有最高点,不稳定)
- 不定 = 马鞍面(鞍点,临界状态)
6.1 合同矩阵 (Congruent Matrices)
定义: 若存在可逆矩阵 \(C\),使得 \(C^T A C = B\),则称 \(A\) 与 \(B\) 合同。
概念比较:合同 vs 相似
| 维度 | 相似 (Similarity) | 合同 (Congruence) |
|---|---|---|
| 公式 | \(P^{-1} A P = B\) | \(C^T A C = B\) |
| 核心不变量 | 特征值 (\(\lambda\)), 迹, 行列式 | 惯性指数 (\(p, q\)), 秩 (\(r\)) |
| 物理意义 | 同一个线性变换在不同基下的表示 | 同一个二次型(能量)在不同坐标系下的表示 |
| 几何直觉 | 拉伸/旋转的倍数没变 | 抛物面的开口方向和凹凸性没变 |
| 联系 | 若 \(P\) 是正交矩阵 (\(P^T=P^{-1}\)),则相似 \(\iff\) 合同 | 实对称矩阵必可合同于对角阵 \(\text{diag}(\pm 1, 0)\) |
避坑:
两个矩阵 \(A, B\) 特征值相同,它们相似,也合同(因为特征值符号肯定一样)。
两个矩阵 \(A, B\) 特征值不同,但正负个数相同,它们合同,但不相似。
6.2 惯性定律 (Sylvester’s Law of Inertia)
定理: 无论你用什么可逆变换(配方法、初等变换、正交变换)把二次型化为标准形,其正系数的个数 (\(p\)) 和 负系数的个数 (\(q\)) 是永恒不变的。
正惯性指数 (\(p\)): 能量增加的维度数量(向上的开口)。
负惯性指数 (\(q\)): 能量减少的维度数量(向下的开口)。
秩 (\(r\)): \(r = p + q\) (起作用的总维度)。
6.3 正定性判据的全景图 (Positive Definiteness)
判断 \(A\) 是否正定(即 \(x^T A x > 0\) 对任意 \(x \neq 0\)),其实是在问:“这真的是一个碗吗?”
四大判据(按解题优先级排序):
特征值判据(最本质):
全为正实数 (\(\lambda_i > 0\))。
(物理意义:在所有主轴方向上,都是往上弯的)
顺序主子式判据(手算最快):
所有顺序主子式 \(D_k > 0\) (\(k=1, \dots, n\))。
(代数意义:高斯消元过程中,主元 pivot 永远为正)
惯性指数判据(配方法):
正惯性指数 \(p = n\) (或者标准形系数全正)。
定义判据:
\(x^T A x > 0\)。
🌌 终章:线性代数的四个基本空间 (The Big Picture)
核心图景:
任何一个 \(m \times n\) 的矩阵 \(A\),都在做一件事:
将 \(n\) 维输入空间 (\(\mathbb{R}^n\)) 里的向量,映射到 \(m\) 维输出空间 (\(\mathbb{R}^m\))。
这个过程中,两个世界被精准地切割成了四块:
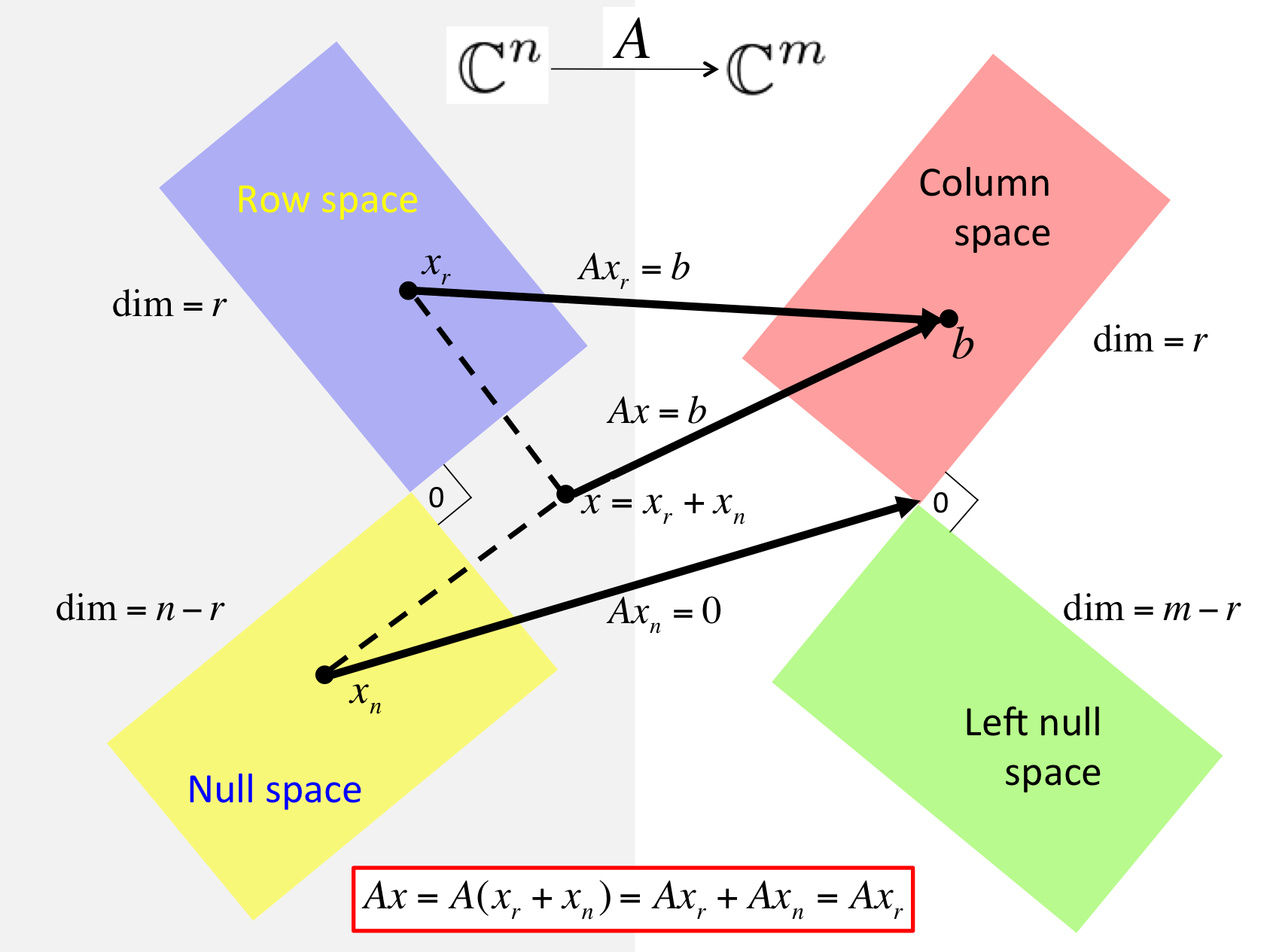
1. 输入世界的切割 (\(\mathbb{R}^n\))
输入向量 \(x\) 被分解为两部分:\(x = x_r + x_n\)。
行空间 \(C(A^T)\) (Row Space):
维数: \(r\) (秩)
身份: “有效输入区”。
理解: 只有落在这个空间里的分量,\(A\) 才会对它处理(拉伸、旋转)。这一部分的信息被保留并传递到了输出端。
零空间 \(N(A)\) (Null Space):
维数: \(n - r\)
身份: “无效输入区” 或 “信息的黑洞”。
理解: 落在这里的分量,\(A\) 直接把它变成了 \(\mathbf{0}\)。这是解方程 \(Ax=0\) 的所有解。
几何关系: 它与行空间正交互补 (\(N(A) \perp C(A^T)\))。
工程意义: 系统中无法被观测到的状态,或者被滤波器滤掉的噪声。
2. 输出世界的切割 (\(\mathbb{R}^m\))
输出向量 \(b\) (或目标向量) 也就处于两个区域之一。
列空间 \(C(A)\) (Column Space):
维数: \(r\) (秩)
身份: “可达区域” (Reachable Set)。
理解: 系统 \(Ax\) 能产生的所有可能的输出。如果 \(b\) 在这里,方程有解。
左零空间 \(N(A^T)\) (Left Null Space):
维数: \(m - r\)
身份: “不可达的禁区”。
理解: 这里的向量 \(y\) 满足 \(A^T y = 0\) (即 \(y^T A = 0\),所以叫“左”零空间)。
几何关系: 它与列空间正交互补 (\(N(A^T) \perp C(A)\))。
工程意义: “误差空间”。当我们做最小二乘法解不可解方程 \(Ax=b\) 时,最小误差向量 \(e = b - p\) 就必须死死地躺在这个左零空间里(因为它必须垂直于列空间)。
3. 总结:线性变换的全过程
当矩阵 \(A\) 作用于向量 \(x\) 时,实际上发生了这三步:
分解: 把 \(x\) 拆成 行空间分量 (有效) 和 零空间分量 (无效)。
毁灭: 零空间分量直接被消灭,变成 0。
映射: 行空间分量被一对一地、可逆地映射到了 列空间。
维度守恒定律 (Rank-Nullity Theorem):
输入的总维度 \(n\) = 活下来的维度 (\(r\)) + 死掉的维度 (\(n-r\))。
4. 为什么叫“左”零空间?(记忆技巧)
Null Space: \(Ax = 0\) (\(x\) 在 \(A\) 的右边)
Left Null Space: \(y^T A = 0\) (\(y^T\) 在 \(A\) 的左边)
这实际上就是 \(A^T\) 的零空间。
最后,感谢学科营的辅导员们,在讨论中给予的耐心指导和启发;也感谢搬运并翻译 MIT 18.06 课程视频的 B 站 up 主,让经典的课程得以被更多人看见和学习。 正是这些来自师长、同好与开源分享的帮助,让这段学习旅程更加丰满。
希望这份带着个人视角与几何偏好的梳理,能给你带来一些不一样的启发。 Enjoy the Journey of LINEAR ALGEBRA! 💐
学习资料参考:
- 致大一新生【2024新版】 - 知乎
- 麻省理工学院—线性代数课(完整版72讲)通俗易懂,绝对是线性代数课程天花板!
- 高数数分代数学科营(SJTU园区)
- 【熟肉】线性代数的本质 - 01 - 向量究竟是什么?
- Visual Kernel - YouTube
整理不易,如果发现笔误或是有更好的理解,欢迎传承! 祝学习顺利 ✨